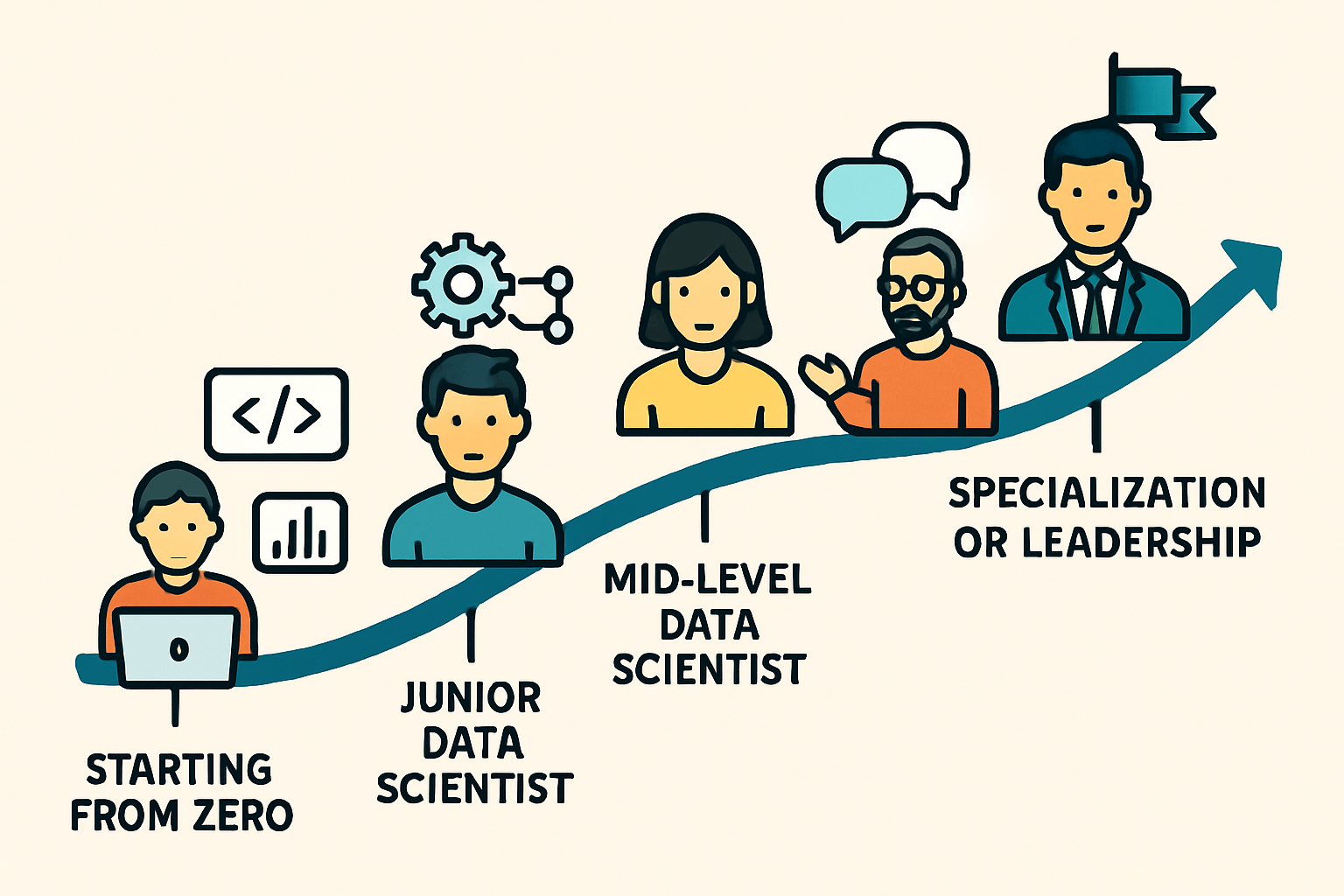
📊 So You Wanna Be a Data Scientist? Here’s What the Career Path Really Looks Like

You have probably heard that data science is one of those fields—cool, in-demand, and supposedly overflowing with high-paying jobs. That part is kinda true. But what does it actually take to go from being someone who barely knows what a CSV file is… to someone building machine learning systems or leading a team of data scientists?
The answer? It is not a straight road. Not even close. The journey depends on who you are, what you’re into, and which rabbit holes you fall down along the way. Still, there are some common stages most people hit, and understanding them makes it way easier to figure out where you’re at—and what comes next.
🧱 Starting From Zero: The “What Even Is This?” Phase
Okay, if you are just getting into data science, it can feel a little overwhelming. There is stats. There is coding. There is machine learning. There is this constant vibe of “everyone else already knows this stuff.” (Spoiler: they don’t.)
To kick things off, most folks start learning basic programming—usually Python, because it is beginner-friendly and has a ton of useful libraries like pandas, NumPy, and scikit-learn. You are not building rocket ships here. It is more like learning how to loop through some numbers, clean up a messy spreadsheet, or make a simple plot.
Alongside that, you need to get your head around basic statistics—mean, median, distributions, all that good stuff. This might sound boring, but honestly, it is super useful once you start dealing with real-world data. You will also want to mess around with SQL, because most data in the real world lives in databases, and SQL is the key to unlocking it.
Now, here is the thing: reading books and watching videos will only take you so far. At some point, you just have to start doing. Download some open datasets. Try a Kaggle beginner competition. Even if you feel clueless, that is normal. The point is to start building some muscle memory.
📊 Becoming a Junior Data Scientist (AKA: “The Cleaner”)
Once you are past the basics, you will probably land your first real gig (or at least an internship). Congrats! Now prepare to clean data. A lot of it.
As a junior data scientist, your job is often to make messy data not-messy. That means figuring out what is missing, fixing typos, merging tables, and doing the kind of data wrangling that makes experienced folks groan. But honestly, this part is underrated—it teaches you a ton about how data actually behaves in the wild.
You will probably start using Jupyter Notebooks daily, maybe get into Git for version control, and work with BI tools like Power BI or Tableau if your team does reporting. You might even try your hand at some simple models—things like linear regression or decision trees. Nothing fancy, but it is a start.
One thing that surprises a lot of people here: communication matters. You cannot just toss a chart at someone and expect them to “get it.” You have to explain stuff in plain English, and tailor how you talk depending on whether your audience is a developer, a product manager, or your boss’s boss.
⚙ Mid-Level: The “Now You Actually Know Stuff” Stage
After a couple of years of grinding through projects, learning from your mistakes, and asking a lot of questions, you hit mid-level. This is where things get way more interesting—and way more complicated.
You are not just analyzing stuff anymore. You are designing models from scratch. You are deciding which data to use and why. You are debugging weird edge cases where your model works great… until it doesn’t.
Tool-wise, you probably know Python (or maybe R) inside and out. You have tried out fancier libraries like XGBoost or TensorFlow. Maybe you have deployed something to AWS or Google Cloud. Big data tools like Spark might be in the mix. You are thinking about pipelines, reproducibility, and all the things that separate a toy project from a production system.
And here is where things get real: you are not working in isolation. You are collaborating with engineers, domain experts, sometimes even legal or ethics folks depending on the data. You start mentoring junior teammates. You start seeing the bigger picture—how data connects to business goals, not just metrics.
🧭 Senior: Strategy Mode Unlocked
At the senior level, you are less “data monkey” and more “data architect.” You are not just handed problems—you help define them.
You are leading projects end-to-end. That means working with stakeholders to figure out what questions matter, building the models, making sure they actually get deployed, and watching them over time to make sure they do not drift into garbage territory.
A lot of senior folks end up specializing in a specific domain—finance, healthcare, e-commerce, whatever. That depth matters, because different fields have totally different quirks. (Like, predicting churn in a mobile game is nothing like detecting fraud in insurance claims.)
You also start owning best practices: making sure models are versioned, code is documented, and everyone is on the same page. You might present insights to leadership, which means you have to know how to pitch ideas, not just explain them. And yeah, you will probably spend more time in meetings than you would like. Welcome to seniority.
🔬 Specializing vs. Leading: Two Roads Diverge
Once you are at that senior level, you usually have a choice. Go deeper or go broader.
If you specialize, you might get into advanced areas like NLP, deep learning, or causal inference. This is where PhDs sometimes shine, but honestly, you can get pretty far through self-study and projects. These roles are often found in research teams, startups, or places experimenting with cutting-edge stuff like large language models.
If leadership is more your thing, you might become a Lead Data Scientist, or manage a team. That means hiring people, setting direction, dealing with deadlines, and translating between execs and engineers. It is a whole different skill set, and not everyone loves it—but if you do, it is a path with real impact.
Some people switch between these modes. Some go all-in on one. There is no single “right” way to level up after this point—it really depends on what excites you.
🚀 Final Thoughts: It Is a Journey, Not a Checklist
So yeah, the data science career path has stages, but it is not like you level up at exact XP points. People bounce around. Some skip steps. Some stay in one stage for years and are totally fine with that.
What matters most? Curiosity. Being okay with not knowing everything. Wanting to learn, experiment, mess up, and try again.
If you are starting out, do not worry about being perfect. Just build stuff. If you are mid-career, look for challenges that stretch you. And if you are already advanced, maybe think about how you can help pull others up behind you.
Because at the end of the day, data science is not just about data. It is about people, questions, decisions—and how we use information to do something smart.
Check Our Courses : Data Science Classroom Training, Data Science Training Course in Bangalore, Python Classroom Training.

